- CFA Exams
- 2026 Level II
- Topic 1. Quantitative Methods
- Learning Module 6. Machine Learning
- Subject 3. Supervised Machine Learning Algorithms
Why should I choose AnalystNotes?
AnalystNotes specializes in helping candidates pass. Period.
Subject 3. Supervised Machine Learning Algorithms PDF Download
Supervised learning depends on having labeled training data as well as matched sets of observed inputs (X's, or features) and the associated output (Y, or target). It can be divided into two categories: regression and classification.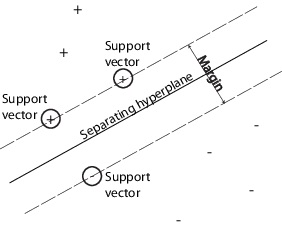
Penalized Regression
It is used for reducing the number of included features in prediction problems.
- If a feature is included, it brings a penalty to the model.
- To be included, a feature must make a sufficient contribution to model fit to offset the penalty from including it.
- Therefore, only important features will remain. Features less pertinent or reflect noise or randomness in the training data set will not be included.
- A model in which each variable plays an essential role is a parsimonious model.
LASSO is a popular type of penalized regression.
Regularization is another one that describes methods to reduce statistical variability in high dimensional data estimation or prediction problems.
Support Vector Machine
Support vector machine is used for classification, regression, and outlier detection. An SVM classifies data by finding the best hyperplane that separates all data points of one class from those of the other class. The best hyperplane for an SVM means the one with the largest margin between the two classes. Margin means the maximal width of the slab parallel to the hyperplane that has no interior data points.The support vectors are the data points that are closest to the separating hyperplane; these points are on the boundary of the slab. The following figure illustrates these definitions, with + indicating data points of type 1, and - indicating data points of type -1.
K-Nearest Neighbor
The idea of K-nearest neighbor (KNN) is to classify a new observation by finding similarities ("nearness") between it and its k-nearest neighbors in the existing data set. It is most often used for classification.
- It is non-parametric.
- It makes no assumptions about the distribution of the data.
- The most challenging job is to define what it means to be "similar".
- A different value of the hyperparameter of the model can lead to different conclusions.
Classification and Regression Tree
Classification and regression tree (CART) can be applied to predict either a categorical target variable, producing a classification tree, or a continuous target variable, producing a regression tree.A binary CART is a combination of an initial root node, decision nodes, and terminal nodes.
- The root node and each decision node represent a single feature (f) and a cutoff value (c) for that feature.
- At each node, the algorithm will choose the feature and the cutoff value for the selected feature that generates the widest separation of the labeled data to minimize classification error.
- The CART algorithm iteratively partitions the data into sub-groups until terminal nodes are formed that contain the predicted label.
To avoid overfitting:
- regularization parameters can be added, or
- a pruning technique can be used afterward.
A CART provides a visual explanation for the prediction (the feature variables and their cut-off values at each node). Its results are relatively straightforward.
Ensemble Learning and Random Forest
Ensemble learning is a technique of combining the predictions from a collection of models. For example, a majority-vote classifier can pick the predicted label with the most votes (generated from different types of algorithms), and assign it to a new data point. Alternatively, one can use the same algorithm but with different training data, and the majority-vote classifier can be used to pick the winner for a classification or an average for a regression.A random forest classifier is a collection of many different decision trees generated by a bagging method or by randomly reducing the number of features available during training. It tends to protect against overfitting but is usually not easy to interpret.
By taking the average result of many predictions from many models (i.e. ensemble learning) one can expect to achieve a reduction in noise as the average result converges towards a more accurate prediction.
User Contributed Comments 0
You need to log in first to add your comment.

You have a wonderful website and definitely should take some credit for your members' outstanding grades.

Colin Sampaleanu
My Own Flashcard
No flashcard found. Add a private flashcard for the subject.
Add